
I've been tackling an equivalence problem with rewritten programs in
StrIoT, our proof-of-concept
stream-processing system.
The StrIoT Logical Optimiser applies a set of rewrite rules to a
stream-processing program, generating a set of variants that can be reasoned
about, ranked, and deployed. The problem I've been tackling is that a variant
may appear to be semantically equivalent to another, but compare (with
==)
as distinct.
The issue relates to the design of our data-type representing programs, in
particular, a consequence of our choice to outsource the structural aspect to a
3rd-party library (
Algebra.Graph). The Graph library deems nodes that compare
as equivalent (again with
==) to be the same. Since a stream-processing
program may contain many operators which are equivalent, but distinct, we
needed to add a field to our payload type to differentiate them: so we opted
for an Integer field,
vertexId (something I've described as a "wart"
elsewhere)
Here's a simplified example of our existing payload type,
StreamVertex:
data StreamVertex = StreamVertex
vertexId :: Int
, operator :: StreamOperator
, parameters :: [ExpQ]
, intype :: String
, outtype :: String
A rewrite rule might introduce or eliminate operators from a stream-processing
program. For example, consider the rule which "hoists" a filter upstream from
a merge operator. In pseudo-Haskell,
streamFilter p . streamMerge [a , b, ...]
=>
streamMerge [ streamFilter p a
, streamFilter p b
, ...]
The original
streamFilter is removed, and new
streamFilters are introduced,
one per stream arriving at
streamMerge. In general, rules may need to
synthesise new operators, and thus new
vertexIds.
Another rewrite rule might perform the reverse operation. But the individual
rules operate in isolation: and so, the program variant that results after
applying a rule and then applying an inverse rule may not have the same
vertexIds, or the same order of
vertexIds, as the original program.
I thought of the outline of two possible solutions to this.
"well-numbered"
StreamGraphs
The first was to encode (and enforce) some rules about how
vertexIds are used.
If they always began from (say) 1, and were strictly-ascending from the
source operator(s), and rewrite rules guaranteed that a "well numbered" input
would be "well numbered" after rewriting, this would be sufficient to rule out
a rewritten-but-semantically-equivalent program being considered distinct.
The trouble with this approach is using properties of a numerical system
built around
vertexId as a stand-in for the real structural problem. I
was not sure I could prove both that the stand-in system was sound and
that it was a proper analogue for the underlying structural issue.
It feels to me more that the choice to use an external library to
encode the
structure of a stream-processing program was the issue: the
structure itself is a fundamental part of the semantics of the program. What if
we had encoded the structure of programs within the same data-type?
alternative data-type
StrIoT programs are trees. The root is the sink node:
there is always exactly one. There can be multiple source (leaf nodes), but
they always converge. Operators can have multiple inputs (including zero).
The root node has no output, but all other operators have exactly one.
I explored transforming
StreamVertex into a tree by adding a field
representing incoming streams, and dispensing with
Graph and
vertexId.
Something like this
data StreamProg = StreamProg StreamOperator [Exp] String String [StreamProg]
A uni-directional transformation from
Graph StreamVertex to
StreamProg
is all that's needed to implement something like
==, so we don't need
to keep track of
vertexId mappings. Unfortunately, we can't fix the
actual
Eq (Graph StreamVertex) implementation this way: it delegates
to
Eq StreamVertex, and we just don't have enough information to fix
the problem at that level. But, we can write a separate
graphEq and
use that instead where we need to.
could I go further?
Spoiler: I haven't. But I've been sorely tempted.
We still have a separate
StreamOperator type, which it would be nice to fold
in; and we still have to use
a list around the incoming nodes, since different operators accept different
numbers of incoming streams. It would be better to encode the correct valences
in the type.
In 2020 I explored iteratively reducing the
StreamVertex data-type to try and
get it as close as possible to the ideal end-user API: simple functions. I
wrote about one step along that path in
Template Haskell and
Stream-processing programs, but concluded that,
since this was not my main
PhD focus, I wouldn't go further. But it was
nagging at my subconcious ever since.
I allowed myself a couple of days exploring some advanced concepts including
typed Template Haskell (that has had some developments since 2020), generalised
abstract data types (GADTs) and more generic programming to see what could be
achieved.
I'll summarise all that in the next blog post.


 Nextcloud is a popular self-hosted solution for file sync and share as well as cloud apps such as document editing, chat and talk, calendar, photo gallery etc. This guide will walk you through setting up Nextcloud AIO using Docker Compose. This blog post would not be possible without immense help from Sahil Dhiman a.k.a.
Nextcloud is a popular self-hosted solution for file sync and share as well as cloud apps such as document editing, chat and talk, calendar, photo gallery etc. This guide will walk you through setting up Nextcloud AIO using Docker Compose. This blog post would not be possible without immense help from Sahil Dhiman a.k.a. 
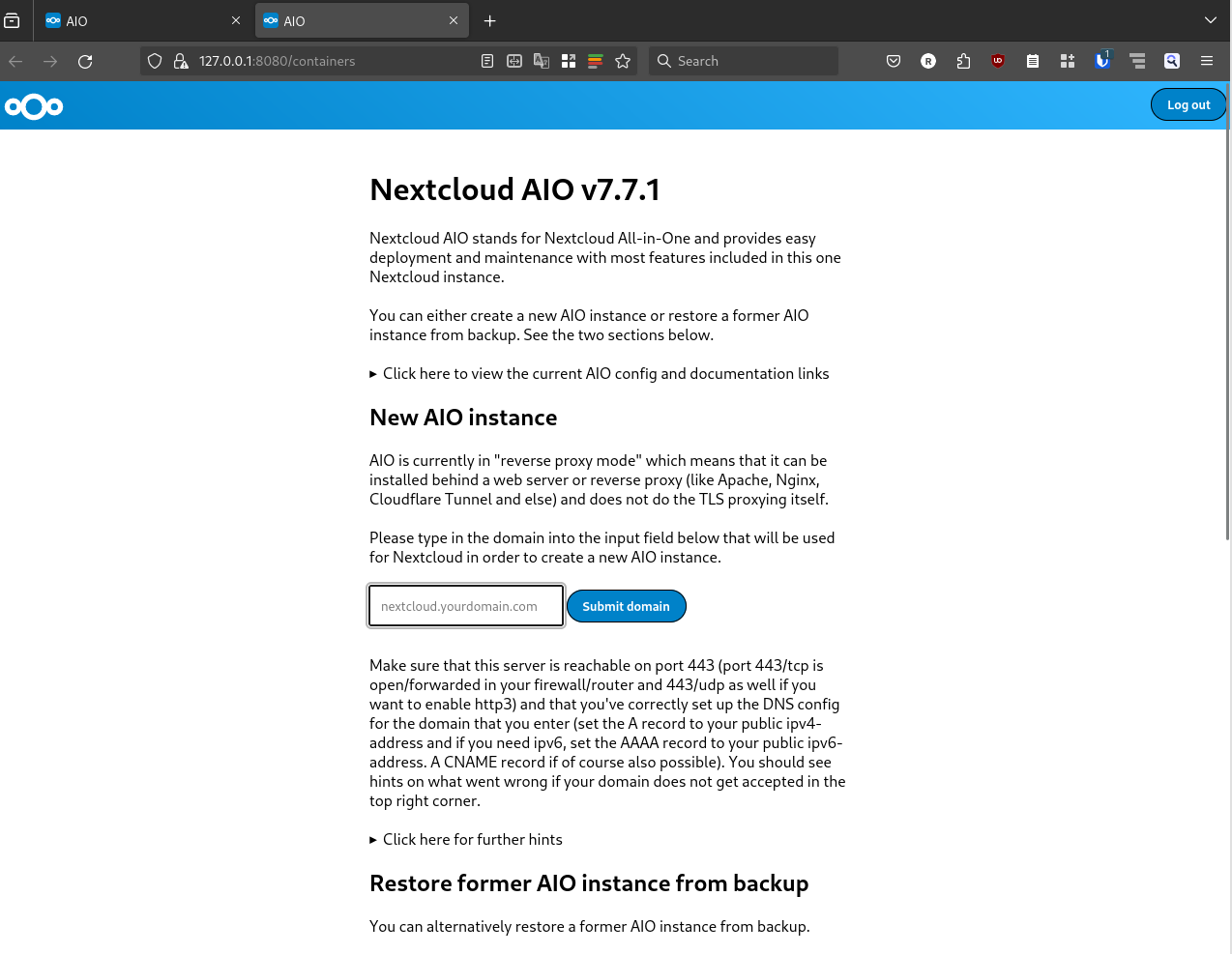
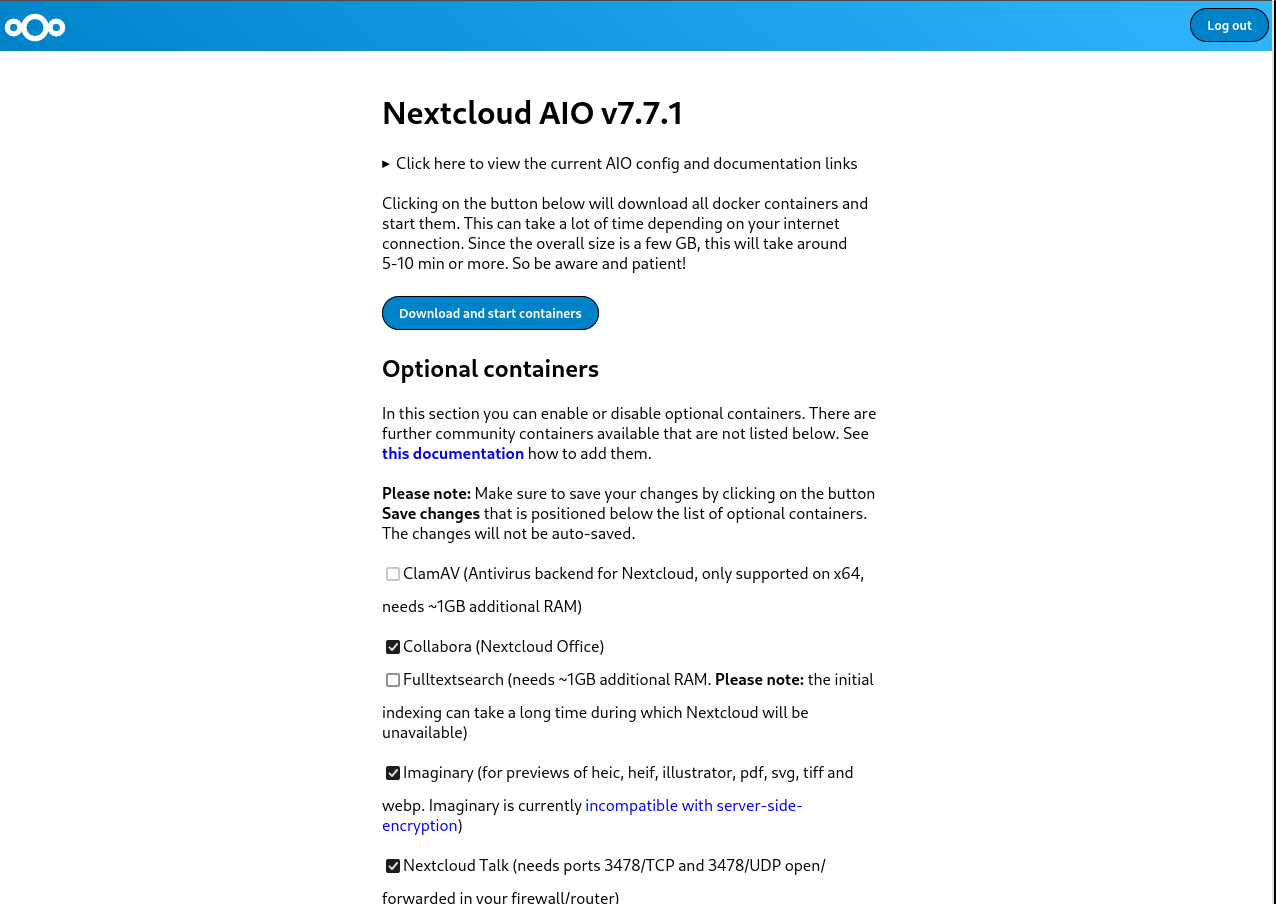


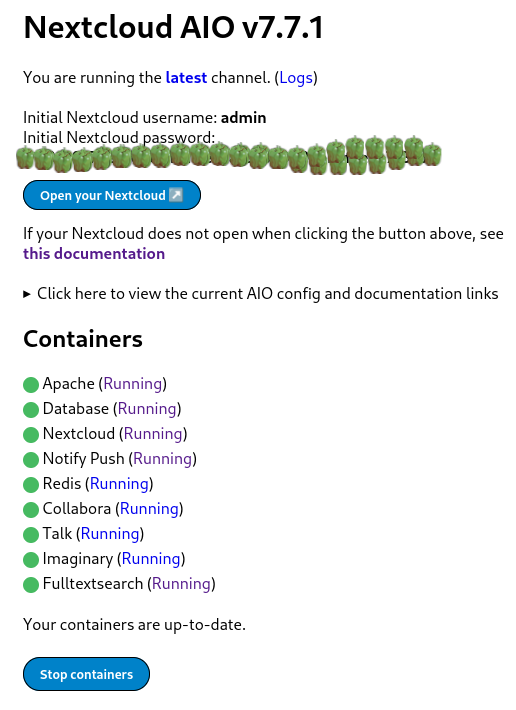
 There's a decent number of laptops with fingerprint readers that are supported by Linux, and Gnome has some nice integration to make use of that for authentication purposes. But if you log in with a fingerprint, the moment you start any app that wants to access stored passwords you'll get a prompt asking you to type in your password, which feels like it somewhat defeats the point. Mac users don't have this problem - authenticate with TouchID and all your passwords are available after login. Why the difference?
There's a decent number of laptops with fingerprint readers that are supported by Linux, and Gnome has some nice integration to make use of that for authentication purposes. But if you log in with a fingerprint, the moment you start any app that wants to access stored passwords you'll get a prompt asking you to type in your password, which feels like it somewhat defeats the point. Mac users don't have this problem - authenticate with TouchID and all your passwords are available after login. Why the difference?

 Check it out
Check it out 

